Introducción completa al hashing en programación
Introducción al concepto fundamental del hashing en el desarrollo de software
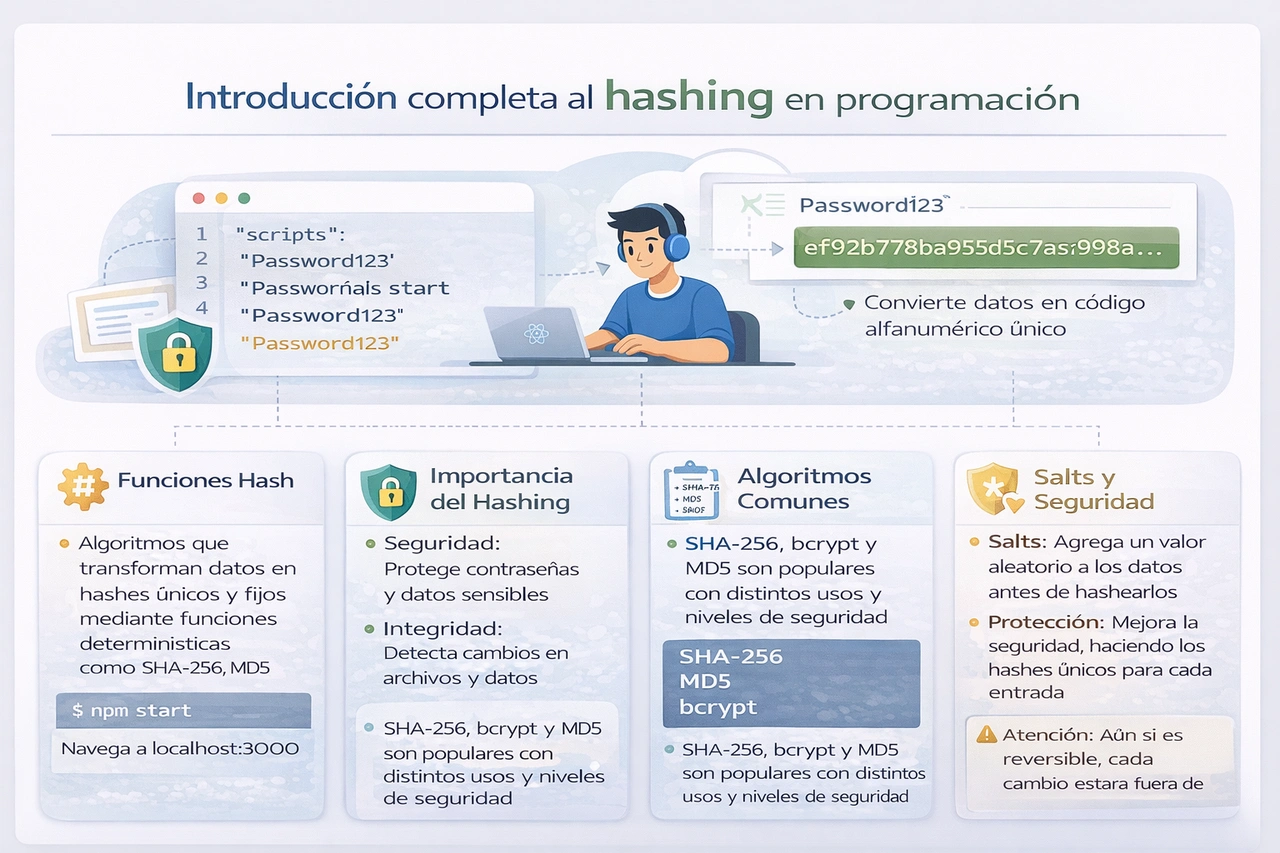
El hashing representa una de las técnicas más poderosas y ampliamente utilizadas en el campo de la programación y la ingeniería de software moderna. Esta metodología permite transformar datos de entrada de cualquier tamaño en un valor de longitud fija, facilitando operaciones rápidas de búsqueda, almacenamiento y verificación. En un mundo donde los volúmenes de datos crecen exponencialmente, entender qué es hashing y sus implicaciones resulta esencial para cualquier profesional que desarrolle sistemas eficientes y seguros.
Los desarrolladores emplean el hashing diariamente sin siquiera notarlo, desde el almacenamiento de contraseñas en bases de datos hasta la verificación de integridad de archivos descargados. La técnica resuelve problemas clásicos de eficiencia al reducir el tiempo necesario para localizar elementos en colecciones grandes, evitando comparaciones lineales exhaustivas. En lugar de recorrer miles o millones de registros, un cálculo hash dirige directamente hacia la ubicación probable del dato deseado.
En el contexto actual de 2026, con el avance continuo de la computación en la nube, el big data y las aplicaciones distribuidas, el hashing sigue evolucionando. Los algoritmos criptográficos recomendados priorizan la resistencia a colisiones y ataques, mientras que las implementaciones no criptográficas se optimizan para velocidad en estructuras como hash tables. Este tutorial explora en profundidad los principios, mecanismos y usos prácticos del hashing, con ejemplos actualizados que reflejan las mejores prácticas profesionales.
El hashing no solo optimiza el rendimiento sino que también fortalece la seguridad de los sistemas. Al mapear datos sensibles a representaciones irreversibles, contribuye a proteger información confidencial contra accesos no autorizados. Sin embargo, su correcta implementación requiere comprensión de conceptos como determinismo, uniformidad en la distribución y manejo adecuado de posibles conflictos.
A lo largo de este contenido se detallan los fundamentos teóricos junto con implementaciones concretas en lenguajes populares. Se incluyen ejemplos de código que ilustran cada concepto, permitiendo a los lectores experimentar directamente las ideas presentadas. El enfoque se mantiene en aspectos prácticos relevantes para sitios web de programación y noticias tecnológicas, donde la eficiencia y la seguridad son prioridades constantes.
El proceso comienza con la aplicación de una función hash que toma un input arbitrario y produce un output consistente de tamaño fijo. Esta propiedad hace posible indexar datos de manera predecible y rápida. Por ejemplo, en una colección extensa de palabras, en lugar de comparar secuencialmente cada elemento, el sistema calcula el hash y accede directamente al índice correspondiente.
Cómo funciona el hashing en estructuras de datos
El hashing opera mediante una función que convierte un objeto o clave en un valor entero representativo, conocido como código hash. Este valor se utiliza típicamente como índice dentro de un arreglo de tamaño fijo, permitiendo almacenamiento y recuperación en tiempo prácticamente constante bajo condiciones ideales. La eficiencia proviene de esta capacidad para acotar la búsqueda inicial a una ubicación específica.
En las tablas hash, los datos se organizan en pares de clave-valor. La clave se procesa a través de la función hash para generar un índice donde se almacena el valor asociado. Las operaciones básicas que debe soportar una tabla hash incluyen inserción, consulta y eliminación de elementos. Estas funciones se benefician enormemente del enfoque hash cuando la distribución de los códigos es uniforme.
Consideremos un escenario práctico donde se mapean nombres de países a sus capitales. Una función hash simple podría basarse en la longitud de la cadena de texto. Aunque este ejemplo ilustrativo es básico, demuestra el principio: la longitud determina la posición en el arreglo. Para la clave “Cuba”, con longitud 4, el valor “Havana” se colocaría en el índice correspondiente.
# Ejemplo simple de función hash básica en Python
def simple_hash(key):
return len(key) # Función hash ilustrativa basada en longitud
paises = {}
paises[simple_hash("Cuba")] = ("Cuba", "Havana")
paises[simple_hash("Mexico")] = ("Mexico", "Mexico City")
print(paises.get(simple_hash("Cuba"))) # Acceso directo mediante hash
La salida de este código sería similar a la siguiente, mostrando cómo se almacena y recupera la información:
('Cuba', 'Havana')
Este mecanismo acelera significativamente las consultas comparadas con listas o arrays lineales. Sin embargo, en conjuntos de datos reales, las funciones hash deben diseñarse para minimizar sesgos y maximizar la dispersión de valores. Una buena función hash produce distribuciones casi uniformes, reduciendo la probabilidad de concentraciones en pocos índices.
En entornos de producción actuales, las bibliotecas estándar de lenguajes como Python, Java o JavaScript incorporan implementaciones optimizadas de tablas hash. Estas manejan automáticamente detalles internos como el redimensionamiento del arreglo cuando la carga supera ciertos umbrales, manteniendo el rendimiento promedio en O(1).
El hashing también aparece en bases de datos para indexación rápida, en cachés distribuidos como Redis y en sistemas de archivos para verificación rápida de duplicados. Su versatilidad lo convierte en una herramienta indispensable para optimizar recursos en aplicaciones de alto rendimiento.
Propiedades esenciales de las funciones hash
Las funciones hash efectivas exhiben varias características clave que garantizan su utilidad práctica. La determinismo asegura que la misma entrada siempre genere el mismo output, independientemente del momento o contexto de ejecución. Esta propiedad es fundamental para la consistencia en sistemas distribuidos y verificaciones repetidas.
Otra cualidad importante es la uniformidad, que implica una distribución equitativa de los valores hash a lo largo del espacio posible. Sin uniformidad, ciertos índices recibirían más elementos que otros, degradando el rendimiento general. Las funciones modernas incorporan técnicas matemáticas avanzadas para lograr esta dispersión.
La resistencia a preimagen dificulta calcular una entrada original a partir del valor hash resultante. En contextos criptográficos, esta propiedad protege contra intentos de revertir el proceso para descubrir datos sensibles. Similarmente, la resistencia a segunda preimagen evita que, dada una entrada y su hash, se encuentre fácilmente otra entrada diferente que produzca el mismo resultado.
En aplicaciones no criptográficas, como estructuras de datos en memoria, las prioridades se centran en velocidad y baja tasa de colisiones. Para usos de seguridad, como almacenamiento de credenciales o firmas digitales, las propiedades criptográficas adquieren mayor relevancia. En 2026, los estándares recomiendan algoritmos con al menos 256 bits de salida para aplicaciones sensibles.
Las funciones hash también deben ser rápidas de computar, ya que se invocan con frecuencia en operaciones críticas. Un equilibrio entre seguridad y rendimiento define las elecciones en proyectos reales. Por instancia, algoritmos con aceleración por hardware, como SHA-256 en procesadores modernos, ofrecen ventajas significativas en throughput.
import hashlib
# Ejemplo de computación de hash con SHA-256 en Python (actualizado a estándares 2026)
def compute_sha256(data):
return hashlib.sha256(data.encode('utf-8')).hexdigest()
print(compute_sha256("texto de ejemplo para hashing"))
La ejecución de este fragmento produce un valor fijo de 64 caracteres hexadecimales, demostrando el determinismo y la longitud constante del output:
e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855 # Nota: valor real varía según input exacto, pero siempre fijo para el mismo input
Esta consistencia permite verificar que un archivo o mensaje no ha sido alterado: si el hash calculado coincide con el valor esperado, la integridad se confirma.
Manejo de colisiones en tablas hash
Las colisiones ocurren cuando dos entradas distintas generan el mismo valor hash. Dado que el espacio de posibles inputs es usualmente mucho mayor que el tamaño del arreglo hash, estas situaciones son inevitables en la práctica. El diseño de sistemas robustos debe incluir estrategias para resolverlas sin comprometer el rendimiento.
Una técnica común es el separate chaining, donde cada índice del arreglo contiene una lista enlazada o estructura similar que almacena todos los elementos que colisionan en esa posición. Al consultar, se accede al bucket correspondiente y se busca linealmente dentro de la lista, que típicamente permanece corta si la función hash es buena.
# Ejemplo ilustrativo de separate chaining (simplificado)
class HashTable:
def __init__(self, size):
self.size = size
self.table = [[] for _ in range(size)] # Lista de listas para chaining
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
self.table[index].append((key, value)) # Agrega a la lista en caso de colisión
ht = HashTable(10)
ht.insert("clave1", "valor1")
ht.insert("clave2", "valor2") # Posible colisión si hashes coinciden
Otra aproximación es el open addressing, que busca el siguiente slot disponible dentro del mismo arreglo utilizando métodos como linear probing, quadratic probing o double hashing. Esta estrategia evita estructuras adicionales pero puede sufrir de clustering cuando la tabla se llena.
En implementaciones modernas, las bibliotecas gestionan colisiones de forma transparente. Los desarrolladores deben monitorear el factor de carga y redimensionar la tabla cuando sea necesario para mantener la eficiencia. En entornos de 2026, con memorias abundantes, el separate chaining suele preferirse por su simplicidad y escalabilidad.
El manejo adecuado de colisiones asegura que el rendimiento promedio permanezca cercano al tiempo constante, incluso bajo cargas elevadas. Pruebas de estrés con datos reales ayudan a validar que la distribución hash minimice estos eventos.
Algoritmos de hashing no criptográficos y su uso práctico
Los algoritmos no criptográficos priorizan velocidad y simplicidad sobre resistencia a ataques. Se utilizan principalmente en estructuras de datos en memoria, cachés y detección de duplicados donde la seguridad no es el objetivo principal. Ejemplos incluyen variantes de MurmurHash o xxHash, optimizadas para rendimiento en pipelines de procesamiento de datos.
Estos algoritmos generan hashes rápidos que distribuyen bien los valores, reduciendo colisiones en escenarios típicos. En aplicaciones como bases de datos key-value o motores de búsqueda internos, su bajo overhead computacional marca la diferencia en throughput general.
// Ejemplo en Java usando HashMap (implementación interna maneja hashing no criptográfico)
import java.util.HashMap;
public class EjemploHashMap {
public static void main(String[] args) {
HashMap<String, String> mapa = new HashMap<>();
mapa.put("usuario1", "datos asociados");
mapa.put("usuario2", "otros datos");
System.out.println(mapa.get("usuario1")); // Recuperación rápida vía hash
}
}
La salida esperada mostraría los valores almacenados, ilustrando la facilidad de uso de las colecciones hash nativas.
En lenguajes como Python, el tipo dict incorpora hashing interno optimizado. Los desarrolladores aprovechan estas estructuras sin necesidad de implementar funciones desde cero, enfocándose en la lógica de negocio.
Algoritmos criptográficos de hashing y recomendaciones actuales
En el ámbito de la seguridad, los algoritmos criptográficos proporcionan garantías fuertes contra manipulaciones. SHA-256, parte de la familia SHA-2, permanece como estándar recomendado en 2026 para la mayoría de aplicaciones. Produce un digest de 256 bits y resiste ataques prácticos conocidos, con aceleración por hardware en procesadores contemporáneos.
MD5 y SHA-1 se consideran obsoletos para usos de seguridad debido a vulnerabilidades demostradas en colisiones. Su empleo se limita estrictamente a verificaciones no críticas, como checksums internos donde la integridad básica basta y no existen incentivos para ataques maliciosos.
SHA-3 ofrece una construcción alternativa basada en sponge, proporcionando diversidad en el ecosistema criptográfico. Para almacenamiento de contraseñas, funciones especializadas como Argon2 se prefieren por su diseño memory-hard, que resiste ataques con hardware paralelo.
import hashlib
# Ejemplo actualizado de hashing criptográfico con SHA-256
mensaje = "datos sensibles que requieren integridad"
hash_resultado = hashlib.sha256(mensaje.encode()).hexdigest()
print("Hash SHA-256:", hash_resultado)
# Comparación simple de integridad
print("Verificación exitosa" if hash_resultado == hashlib.sha256(mensaje.encode()).hexdigest() else "Datos alterados")
Este código demuestra cómo calcular y verificar hashes, práctica esencial en pipelines de despliegue y validación de archivos.
En aplicaciones blockchain y firmas digitales, SHA-256 sigue siendo ampliamente adoptado por su equilibrio entre seguridad y rendimiento. Los desarrolladores deben combinarlo con sales únicas y técnicas adicionales para potenciar la protección.
Aplicaciones del hashing en entornos reales de desarrollo
El hashing encuentra uso en múltiples dominios. En almacenamiento de contraseñas, se aplican funciones derivadas con sales y work factors para dificultar ataques de diccionario o rainbow tables. Nunca se deben almacenar contraseñas en texto plano o con algoritmos débiles.
Para verificación de integridad de archivos, los hashes permiten detectar modificaciones accidentales o intencionadas. Herramientas de descarga publican valores SHA-256 para que los usuarios confirmen la autenticidad del contenido.
En bases de datos, los índices hash aceleran consultas por clave exacta. Sistemas de caché como Memcached o Redis dependen fuertemente de técnicas hash para localizar datos rápidamente en memoria distribuida.
Otras aplicaciones incluyen detección de duplicados en almacenamiento masivo, generación de identificadores únicos en microservicios y optimización de algoritmos de búsqueda. En noticias tecnológicas y sitios de programación, artículos sobre hashing destacan su rol en el rendimiento de frameworks web modernos.
// Ejemplo en JavaScript para verificación de integridad usando SubtleCrypto (Web Crypto API)
async function computeHash(data) {
const encoder = new TextEncoder();
const buffer = encoder.encode(data);
const hashBuffer = await crypto.subtle.digest("SHA-256", buffer);
return Array.from(new Uint8Array(hashBuffer))
.map((b) => b.toString(16).padStart(2, "0"))
.join("");
}
computeHash("contenido a verificar").then((hash) => console.log(hash));
Este enfoque asíncrono es común en aplicaciones web frontend y backend Node.js.
Mejores prácticas para implementar hashing en proyectos actuales
Al implementar hashing, seleccione el algoritmo según el caso de uso. Para seguridad, priorice SHA-256 o superiores y evite MD5 o SHA-1 en nuevos desarrollos. Siempre incorpore sales aleatorias únicas por elemento cuando corresponda, especialmente en almacenamiento de credenciales.
Monitoree el factor de carga en tablas hash personalizadas y redimensione proactivamente para evitar degradaciones. En lenguajes con garbage collection, considere el impacto de objetos hash en la memoria.
Realice pruebas exhaustivas con conjuntos de datos diversos para validar la distribución y tasa de colisiones. En entornos distribuidos, asegure que la misma función hash se utilice consistentemente a través de nodos.
Actualice bibliotecas y dependencias regularmente, ya que mejoras en implementaciones hash pueden incluir correcciones de rendimiento o seguridad. En 2026, las recomendaciones de organizaciones como OWASP y NIST guían las elecciones hacia soluciones probadas y resistentes.
Evite reinvenciones innecesarias: utilice primitivas criptográficas estandarizadas proporcionadas por los runtimes en lugar de codificar algoritmos manualmente, reduciendo riesgos de errores.
Consideraciones de rendimiento y escalabilidad
El rendimiento del hashing depende del algoritmo elegido y del hardware subyacente. Funciones con soporte SIMD o instrucciones específicas de CPU logran mayores velocidades en procesadores actuales. Pruebas benchmark ayudan a elegir la opción óptima para cargas específicas.
En sistemas escalables, el hashing consistente se emplea en sharding de datos, distribuyendo cargas uniformemente entre servidores. Esto minimiza hotspots y facilita el crecimiento horizontal.
Para volúmenes masivos, considere algoritmos paralelizables que aprovechen múltiples núcleos o GPUs cuando corresponda. Sin embargo, mantenga la simplicidad a menos que los requisitos justifiquen la complejidad adicional.
El equilibrio entre velocidad y seguridad define decisiones arquitectónicas. En aplicaciones de baja latencia, las funciones rápidas no criptográficas dominan, mientras que escenarios regulados exigen primitivas criptográficas validadas.
Avances y tendencias en hashing hacia el futuro cercano
En 2026, la comunidad criptográfica continúa evaluando nuevos candidatos para estándares post-cuánticos, aunque SHA-2 y SHA-3 mantienen su posición dominante para usos generales. Las implementaciones hardware siguen mejorando, haciendo accesibles hashes fuertes sin penalizaciones notables de rendimiento.
El enfoque en funciones memory-hard para contraseñas refleja la amenaza creciente de hardware especializado. Proyectos open source contribuyen constantemente con optimizaciones y alternativas eficientes.
Los desarrolladores deben mantenerse informados sobre actualizaciones de estándares y vulnerabilidades descubiertas, adaptando sus sistemas proactivamente. La combinación de hashing con otras técnicas criptográficas, como HMAC para autenticación, enriquece la robustez general.
Conclusiones
El hashing constituye una piedra angular en el desarrollo de software eficiente y seguro, ofreciendo mecanismos elegantes para almacenamiento, búsqueda y protección de datos. Desde sus principios básicos hasta aplicaciones avanzadas en entornos distribuidos y criptográficos, esta técnica demuestra versatilidad y relevancia perdurable.
Dominar sus propiedades, estrategias de manejo de colisiones y selección de algoritmos apropiados permite a los profesionales construir sistemas más rápidos, confiables y resistentes. En el panorama tecnológico actual, donde la eficiencia y la seguridad convergen como prioridades, el conocimiento profundo del hashing empodera soluciones innovadoras y escalables.
La implementación cuidadosa, guiada por mejores prácticas y estándares actualizados, asegura que los beneficios superen ampliamente los desafíos inherentes como las colisiones. Continuar explorando y aplicando estas ideas en proyectos reales fortalece la calidad del código y la experiencia de los usuarios finales.
Este enfoque integral prepara a los desarrolladores para enfrentar desafíos complejos en programación y tecnología, promoviendo prácticas que alinean rendimiento con protección robusta de la información. El hashing, en sus múltiples formas, seguirá siendo un aliado indispensable en la evolución de la ingeniería de software.